Win The Data War: How normal people can survive and thrive in the data abundance era
- Jeff Hulett
- Nov 29, 2023
- 66 min read
Updated: Jan 16

There is a gap between most people's statistical understanding and the practice of data science. The tech world has an unsavory drug culture-inspired name for their customers --- you are known as a "user." Then, to complete the analogy, a tech company could devolve into being a "dealer" or a "pusher." A tech company focuses on the "user interface" when operating a smartphone and the "user experience" driving the app’s "user engagement.” Of course, tobacco companies use the same language. However, instead of smartphones and apps delivering data, tobacco companies use cigarettes to deliver nicotine.
The challenge is that data, unlike nicotine, cannot be avoided. Data is at the core of how our brain functions. Our brain naturally attends to data to sustain our life. The statistics taught in school are not as useful as they could be to guide individual "users" to make the most of the data in our lives. This article provides the bridge. After walking the bridge, you will receive decision confidence via a practical and intuitive statistical understanding. Your decision confidence is fortified by tools from data science and business practitioners. Many resources are furnished to help you dig deeper and make the language of data your Information Age superpower!
Yes, I have been on the dealer side. But now it is time to help the users fight back with data and decision-making confidence.
We will explore gaining knowledge from data by harnessing the power of statistics. Statistics is the language of data. A statistical language starting point is provided by building upon the time-tested statistical moments framework. It shows why learning the world through the data lens is helpful and increasingly necessary.
Just like grammar rules for language, statistical moments are essential for understanding our data-informed past as a guide for navigating the future. As those statistical grammar rules become routine, you will effectively understand the data defining our world. This understanding grows to be a permanent feature guiding your success. Data, as representing our past reality, contains nuance, exceptions, and uncertainties adding context to that historical understanding. The statistical moments framework helps unlock the power of our data.
We begin by making the case for data and why learning the language of data is important. Tools, called 'personal algorithms,' are introduced to help you transform your data. Then, we will jump into the major statistical moments' building blocks. They serve as the article's table of contents. Intuitively understanding these moments provides the grammar and a path to understanding your past reality. The path includes an approach to identify and manage inevitable uncertainties and potential ignorance. Context-strengthening examples and historical figures are provided from science, personal finance, business, and politics.
The Data Explorer's Journey Map
Introduction: The case for data and the data bridge
Don't be a blockhead → 0th moment: unity
Our central tendency attraction → 1st moment: the expected value
Diversity by degree → 2nd moment: the variance
The Pull of the Outliers → 3rd moment: the skewness
The tale of tails → 4th moment: the kurtosis
Fooling ourselves, a moment of ignorance
Conclusion, appendix, and notes
Please follow the links for more formal definitions of the statistical moments. Knowledge of statistics is helpful but not necessary to appreciate this article. For a nice descriptive, probability, and inferential statistics primer, please see this link. Thanks to Liberty Munson, Director of Psychometrics at Microsoft, for providing the excellent primer.
About the author: Jeff Hulett is a career banker, data scientist, behavioral economist, and choice architect. Jeff has held banking and consulting leadership roles at Wells Fargo, Citibank, KPMG, and IBM. Today, Jeff is an executive with the Definitive Companies. He teaches personal finance at James Madison University and leads Personal Finance Reimagined - a personal finance and decision-making organization. Check out his latest book -- Making Choices, Making Money: Your Guide to Making Confident Financial Decisions -- at jeffhulett.com.
Data and algorithms are different.
I offer this disclaimer because data and algorithms are often confused. Data represents our past reality. Algorithms transform data. They are different. Data has already happened. An algorithm is a tool to transform data intended to predict and impact the future. An organization’s data-transforming algorithm may be helpful to you - especially when your attentions are aligned with that algorithm’s objective. More often today, an organization’s data-transforming algorithm is even more helpful for optimizing some other objective -- such as maximizing shareholder profit or filling political party coffers. Please see the appendix for more context.
But algorithms are not just for organizations trying to sell you stuff. You should identify, test, and periodically update an intuitive set of personal algorithms to make a lifetime of good decisions. Personal algorithms are an intuitive set of rules you use to transform your data. Your personal algorithms are either informal or, more necessary today, enhanced with the help of personal decision tools. Together, we will build an intuitive understanding of data in the service of building your personal algorithms. Our focus is on using the statistical moments as a bedrock for that data understanding. During our data exploration, Bayesian Inference and choice architecture tools like Definitive Choice will be introduced. Choice architecture is a helpful tool for implementing your personal algorithms.
Choice Architecture and Personal Algorithms.
Behavioral economist and Nobel laureate Richard Thaler said:
“Just as no building lacks an architecture, so no choice lacks a context.”
A core behavioral economics idea is that all environments in which we need to make a choice have a structure. That structure impacts the decision-maker. There is no "Neutral Choice" environment. People may confuse not making a decision as safer. Not making a decision is no more safe, and possibly much less safe, than actively making a decision. The choice environment is guided by the subtle incentives of those providing the environment. Those providing the environment almost never have incentives fully aligned with your welfare.
Once you accept this premise, you will see the world differently. Let's explore a retirement savings example. Many companies provide 401(k)s or similar tax-advantaged retirement plans as a company benefit. As part of the new employee onboarding process, the company provides their choice architecture to guide the employee to make a voluntary retirement selection. Next, we will explore the retirement plan selection process from both the employer's and the employee's perspective.
A company may provide many mutual funds and investment strategies to assist employees in making a retirement plan decision. Their rationale for the volume of choices is partly the recognition that all retirement needs are unique to the individual's situation. The company does not want to influence the employee with a particular retirement strategy. They want to ensure the employee's choice is informed by a wide array of possible alternatives. The well-intended volume of choices should help the employee. But does it?
But let’s look at it from the employee’s standpoint. This choice environment, with its high volume of complicated-looking alternatives, seems noisy and overwhelming. Even though, the plan administrator likely provides some means of filtering those choices. The overwhelming noise perception occurs because the employee is not accustomed to making retirement plan decisions. The volume of alternatives amplifies the impact upon their negative perception. Also, their attention is more focused on being successful in their new job. In fact, research shows, this sort of choice environment discourages the employee from selecting ANY retirement plan. A typical employee narrative may be: "300 choices!? Wow, this looks hard! Plus, I have so much to do to get onboarded and productive in my new company. I will wait until later to make a decision." ... and then - later never comes.
A complicated, overwhelming choice environment causes savings rates to be less than what they otherwise could have been. A compounding factor is that, traditionally, the default choice provided by the employer is for the employee NOT to participate in the retirement program. This means that if the employee does not complete some HR form with a bunch of complicated choices, then they will not save for their own retirement. Thus, the overwhelming noise perception is captured in the behavioral truisms:
A difficult choice that does not have to be made is often not made.
- and -
Not making a choice is a choice.
Even though, like in the case of a retirement plan with employer matching and tax advantages, making almost ANY choice would be better than making no choice.

Regarding company incentives, the company will usually match employee contributions to the retirement plan. So if the employee does not participate, the company will not need to contribute. An employee not participating reduces the company's retirement expense. Thus, the unused match will drop to the bottom line and be available to the equity owners. A company's default choice environment is a function of its complex incentives and self-interests. As discussed in the appendix, the employee is only one of four beneficial stakeholders vying for the attention of company management. Thus, based on a one in four equally weighted average, management's stakeholder balance will not favor the employee.
Regarding the company’s management relationship with its stakeholders, an unused benefit is like a double win - providing two for the price of one!
Win 1 – The company offered the employee the benefit. It is up to the employee to decide how to use the benefit. Management narrative: Good for the employee.
Win 2 – If the employee does not use the benefit, then the unused benefit drops to the bottom line. Management narrative: Good for the shareholding equity owner.
Retirement planning is one of many choice-challenged examples we face daily. Research suggests that thousands of choices are made daily. [i-a] The essential point is that modern life is characterized by overwhelming data abundance to influence those choices. As we discuss later, our smartphones and other devices are like data firehoses - spewing data on the user. Whether retirement or many other important choices, the volume and complexity of those choices often discourage normal people from making any choice. The default has become the standard and that standard is set by organizations usually not fully aligned with your welfare.
In the world of corporate marketing and accounting, they have a word for when the choice environment enables a consumer NOT to take advantage of an earned benefit. That word is appropriately called - Breakage. As an example, airline credit cards are huge money makers. Why? A significant source of revenue comes from the airline travel benefit earned by the customer but then not utilized. Plus, breakage does not occur by accident - company choice architecture enables breakage. With airline credit card reward programs, there is nothing that requires the rewards card to provide more difficult-to-obtain travel benefits than a much easier-to-obtain cash equivalent. It is the difficulty that causes the breakage.
So, a choice architecture geared to your needs is essential for building your personal algorithm. The choice architecture of a company is likely motivated by objectives NOT necessarily aligned with your welfare. As such, you should take charge of your own choice environment with choice architecture of your own!
To explore AI and personal algorithms in the context of making a pet decision, please see:
Data is the foundation.
On the way to implementing or updating your personal algorithms, we must begin by providing a bridge to build your data foundation. Personal algorithms are greatly improved when the beneficiary of those algorithms has a solid understanding of data and statistics. This is the essential data bridge - spanning from the land of choice-challenge to the successful decision-making happy place.
Motivation connects our past data
to our algorithmic-influenced future

In my undergraduate personal finance class, part of the curriculum is to help students understand the interaction of data, the power of organizational algorithms, and how to leverage or overcome them with a personal algorithm-enhanced decision process.
1. Introduction: The case for data and the data bridge
From data scarcity to data abundance
In the last half of the 20th century, the world shifted from the industrial era to the information era. The changing of eras is very subtle. For those of us who lived through the era change, it is not like there was some official government notice or a “Welcome to the information era” party to usher in the new era. It just slowly happened – like a “boil the frog” parable - as innovation accelerates and our cultures' adapt. Era changeovers are very backward-looking. It is more like a historian observing that so much had changed that they decided to call the late 20th century as when the information era started.
This big change requires people to rethink their relationship with data, beliefs, and decision-making. Prior to the information age, data was scarce. Our mindset evolved to best handle data scarcity over many millennia. In just the last few decades, the information age required us to flip our mindset 180 degrees. Today, the data abundance mindset is necessary for success. Our genome WILL catch up some day…. Perhaps in a thousand or more years as evolution does its' inevitable job. Until then, we need to train our brains to handle data abundance. The objective is to show you a path to handle data abundance. Cognitive gaps, such as that created by the difference between our data scarcity-based genome and our data abundance-expected culture have only widened during the information era.
In the industrial era, computing power was needed and not yet as available. As a result, math education taught people to do the work of computers. In many ways, people were the gap fillers for furnishing society's increasing computational needs. Our education system trained people to provide the needed computational power before powerful computers and incredible data bandwidth became available.
Over time, digital data storage has been increasing. However, even during the industrial era, those data stores still took effort to locate. Data was often only available to those with a need to know or those willing to provide payment for access. The average person during the industrial era did not regularly interact with data outside that observed in their local, analog life. Scarcity, as an economic lever, was the providence of data during the industrial era.
The information era is different. Today, powerful computers exist and computing power is both ubiquitous and inexpensive. Digital data stores are no longer like islands with vast oceans around them for protection. Data stores are now among easy-to-access cloud networks. Also, many consumers are willing to trade personal data and attention for some financial gain or entertainment. While this attitude is subject to change, this trade seems to be working for both the consumers and those companies providing the incentives. "The Dopamine Trade," shown in the next graphic, describes how the AI and human brains develop symbiosis by the intermediating agents leveraging the human reward neurotransmitter. Data abundance is the defining characteristic of today's information era. Success comes from understanding your essential data and applying that data with available computing technology.

See: A Content Creator Investment Thesis - How Disruption, AI, and Growth Create Opportunity This article provides background for why people are willing to give up their data to the social media platforms.
For most people, today's challenge is less about learning to do the work of a computer as taught during the industrial age. Today's challenge concerns using abundant data, leveraging technology, and optimizing our attention in the service of human-centered decisions. Our formal math education systems have been slow to change and tend to favor former industrial era-based computation needs over information era-based data usage. [i-b] This is unfortunate but only emphasizes the need to build and practice your statistical understanding even if you did not learn it in your formal education. Will our education systems eventually get updated? Sure they will. However cultural change is led by individuals. In this case, those individuals should be demanding data-focused education. Legacy cultural systems, such as our industrial age-based education system, often do not quickly change. They just fade away as their irrelevance grows. Why should we NOT expect the current education system to lead the change? Upton Sinclair (1878-1968) authored "The Jungle" and was an impactful cultural influencer in his day. Mr. Sinclair's timeless aphorism suggests why the education system should not be expected to lead a math curriculum change. [i-c]
"It is difficult to get a man to understand something, when his salary depends on his not understanding it."
The big change – From data scarcity to data abundance
Data scarcity was when the most challenging part of a decision was collecting data. The data was difficult to track down. It was like people were data foragers, where they filled a basket with a few pieces of difficult-to-obtain data they needed for a decision. Since there was not much data, it was relatively easy to weigh and decide once the data was located.

Data abundance has changed our relationship with data 180 degrees in just the last few decades. Consider your smartphone. It is like the end of a data firehose. Once the smartphone is opened, potentially millions of pieces of data come spewing out. Plus, it is not just smartphones, data is everywhere. But it is not just the volume of data, it is the motivation of the data-focused firms. The data usage has a purpose and that purpose is probably not your welfare.
"The best minds of my generation are thinking about how to make people click ads. That sucks." - Jeff Hammerbacher, a former Facebook data leader.

The challenge is no longer foraging for data. Our neurobiology, as tuned by evolution, is still calibrated to the data scarcity world. It is like no one told our brains that how we make decisions is dramatically different today. The challenge is now being clear about which of the overwhelming flood of data is actually needed. The challenge is now to curate data, subtract the unneeded data, and use the best decision process. Unfortunately, the education curriculum often teaches students as if we are still in the data scarcity world.
Economics teaches us that which is scarce is that which creates value. So, since data is abundant, then what is it that creates value? In the information era, it is scarce human attention that creates value for companies trading in data abundance.
For a "Go West, Young Man" decision made during the 1800s as compared to a similar decision today, please see the article:

The Big Change: Scarcity, as an economic lever, has changed from data to attention.
Our past reality is diverse
Our world can be interpreted through data. After all, data helps people form and update their beliefs. When we were young, our beliefs were originated by our families and communities of origin. Those original beliefs are incredibly impactful. For some, those beliefs created a great start to life. For others, they may have been more harmful than helpful. However, regardless of the degree to which original beliefs are helpful or harmful, all healthy adults must come to own and update those beliefs as situations warrant. For the childhood belief updating framework, please see:
This makes statistics the language of interpreting our past reality in the service of updating those beliefs. Like any other language, the language of statistics has grammar rules. Think of statistical moments as the grammar for interpreting our past realities. The better we understand the grammar rules, the better we can:
Learn from our past reality,
Update our beliefs, and
Make confidence-inspired decisions for our future.
'Past reality’ may be a nanosecond ago, which was as long as it took for the light of the present to reach our eyes. Alternatively, ‘past reality’ could be that learned from our distant ancestors. A group of people is known as a population. Populations are mostly described across diverse distributions. A distribution describes unique factors of a population and how often those unique factors occur. How often those unique factors occur relative to the total is also described as a probability. Understanding the probabilities based on your past reality helps you infer future outcomes. While people may share some similarities, we also share incredible uniqueness. It is understanding that uniqueness that is at the core of statistics and helping us to make good decisions.
Diversity goes beyond typical characteristics, like gender, race, and eye color. Even more impactful is our diverse behavior generated by the uncertainty we face in our lives. Those uncertainty characteristics include:
a) the incomplete and imperfect information impacting most situations,
b) the dynamic, interrelated nature of many situations, and
c) the unseen neurobiological uniqueness we each possess.
This means even the definition of rationality has been redefined. There was once a belief that rationality could be calculated as a single point upon which all people converge. This 'robotic' view of rationality was convenient for mathematics but did not accurately describe human behavior. Instead, today, rationality is more accurately understood through the eyes of the diverse beholder. The same individual is often diverse across different situations because of uncertainty, framing, and anchors. This means the “you” of one situation is often different than the “you” of another situation because of our state of mind at the time the situation is experienced and how seemingly similar situations inevitably differ. Certainly, the different "us" of the same situation and time are also divergent, owing to individual neurodiversity.

This graphic is an excerpt from the article: Becoming Behavioral Economics — How this growing social science is impacting the world
Our hunt is to understand the population's diversity by learning about its past reality and by applying our unique and varying rational perspectives. But rarely can data be gathered on the entire population. More often, we must rely on samples to make an inference about the population. Next, the challenges of reducing the population to a sample are explored.
Tricky samples and cognitive bias
The sample data from others in the population may be challenging to interpret. That is the subject of the following statistical moments sections. Owing to situational uncertainty, framing, and anchors, our brains may play sampling tricks on us. These tricks have grown in significance because of how the information era has evolved. These tricks may lead us to conclude the sample data we used to confirm a belief is representative and appropriate to make an inference. It takes careful inspection to guard against those tricks, called confirmation bias. Next is a typical decision narrative descriptive of the environment leading to confirmation bias and a less-than-accurate decision:

This narrative is typical of how people experience their decision environment and motivations. The challenge is that the past outcome is a single observation in the total population. Your sample size of one is likely too small to make a robust inference. To be clear, this does NOT mean your past experience has no decision value... of course it does. Our evolutionary biology is wired such that being inaccurate and alive is better than being accurate and dead. However, blindly following our past experiences as a guide to the future may not include other past realities to help inform our decisions. Thus, except for life and death situations, using the wisdom of the crowd is often better than not.
When a sample size of one is the best decision approach: When my children were young, my wife and I took family trips to Manhattan near Central Park. Our home was in a much less dense Washington DC suburb. So our New York City experience was very different than our suburban customs. We took long walks on the gridded Manhattan streets. Not infrequently, a car would not yield the right away to us walkers. It was scary. We needed to have our heads on a swivel before stepping off the curve.
This annoyed my children. They wanted to know why we had to be so careful because it was the cars that broke the rules. My response was: “It is always better to be wronged and alive than right and dead.”
With the exception of those life-and-death examples, the sample size of many is a more accurate decision approach. Robyn Dawes (1936-2010) was a psychology researcher and professor. He formerly taught and researched at the University of Oregon and Carnegie Mellon University. Dr. Dawes said:
"(One should have) a healthy skepticism about 'learning from experience.' In fact, what we often must do is to learn how to avoid learning from experience."

Properly understanding your past reality in the present decision context is doable with the appropriate decision process. Part of being a good data explorer is using a belief-updating process including a suitable integration of our and others' past reality. A proper decision process helps you avoid confirmation bias and achieve conviction in your decision confidence.

Think of confirmation bias as a mental shortcut gone bad. Most mental shortcuts provide effective or at least neutral heuristic-based signals. [iii] Referring back to that car lesson with my children, my instinct to instruct my children for safety is a helpful and instinctive heuristic. I seek to protect my children without really thinking about it - well, except for that pithy response about the right and the dead. But confirmation bias occurs when a mental shortcut leads us to make a poor decision. As the next graphic illustrates, confirmation bias occurs when only a subset of evidence is used to make a decision. While the current set of information may be convenient and apparently confirms a previous belief, the decision-maker ignores a fuller set of data that may be contrary to the existing belief. This kind of cherry-picking bias leads to a reasoning error called an error of omission. Errors of omission are tricky because technically the subset of information is not wrong, it is simply incomplete to draw the appropriate conclusion.

A politician's example for reasoning errors: Fact-checking is often done to detect incorrect statements of the data the politician provides. A false statement is also known as an error of commission. However, the challenge is not necessarily what the politician said, but what the politician did NOT say. Politicians regularly engage in providing incomplete fact sets. Errors of omission are a) different than their error or commission cousins and b) generally tolerated or not detected by the public. Politicians regularly and conveniently leave out data - an error of omission - when trying to sell a particular policy or campaign plank.
Could you imagine a politician saying, “Here are all the reasons why this is a great policy decision! But wait! Here are several other reasons that may make this policy decision risky and potentially not effective. There are many tradeoffs. The chance of success depends greatly on the complex and unknowable future!” We value leaders who govern honestly. There are complex facts and tradeoffs necessary to make a great decision. But a wishy-washy candidate would struggle to get elected. Political theater and a complete rendering of complex policy decisions are very different.
It is not clear whether the politician is selfishly motivated to commit errors of omission, as part of a goal to grow their power base. Alternatively, those errors may be selflessly motivated, recognizing that most people need help clarifying complex situations. It is likely some of both. However, regardless of the politician's motivation, errors of omission are rampant.
Bertrand Russell (1872-1970) - the late, great mathematician and philosopher's timeless aphorism reminds us of the politician's reasoning challenge:
"The whole problem with the world is that fools and fanatics are always so certain of themselves, and wiser people so full of doubts."
Being on the lookout for confirmation bias is essential for the successful data explorer. Confirmation bias is a type of cognitive trick called cognitive bias. All people are subject to cognitive biases. Mental shortcuts, also known as heuristics, are a helpful feature of the human species. Their related cognitive bias cousins are a heuristic byproduct and something we all share. The transition to the data-abundant and attention-scarce era has caused those byproduct cognitive biases to be more impactful upon decision-making.
A great cognitive bias challenge is that they come from the emotional part of our brain lacking language. [iv-a] This means that other than vague feelings, we have no signal to warn us when we are under the spell of a cognitive bias. In the last typical decision narrative, the pain or joy of those outcomes was remembered. The challenge is that those emotions have no weight as an input to the current decision. Also, that feeling has no way to integrate with all the other data you need to make the best decision. Confirmation bias is when we do not weigh our data signals - inclusive of emotion - correctly. Inaccurate weighting goes both ways — one may be under-confident or over-confident when interpreting emotion-based data.
In order to learn and infer from our past reality, one must either have a) an unbiased sample or b) at least understand the bias so inferential corrections can be made. Statistics help us use a wider set of data and properly integrate our own experience, including those vague feelings. This is in the service of taking a less biased, outside-in view to better understand our data.

Please see the following VidCast for more information on how confirmation bias leads to reasoning errors. This VidCast shows the slippery slope of how confirmation bias may devolve to cancel culture and allowing others to determine an individual’s self-worth. Political leaders may aspire to this level of followership. Social Media echo chambers are a hotbed for confirmation bias and cancel culture.
Being Bayesian and the statistical moments' map
In the next few paragraphs, Bayesian Inference will be introduced. Consider this a starting point. You will want to circle back to Reverend Bayes' work after walking through the statistical moments framework found in the remainder of this article. That circle-back resource is provided next.
The story of Thomas Bayes is remarkable. He lived over 250 years ago and created an approach to changing our minds. The Bayesian approach disaggregates the probabilistic steps to update our beliefs. Effectively changing our minds is a core human challenge - mostly unchanged by evolution. Belief updating is a challenge in today’s information-overloaded world. Bayes' treatise is a beacon for helping people change their minds when faced with uncertainty. Being a successful data explorer often requires us to actively manage our cognitive biases by curating and refining valid data and subtracting the data that is irrelevant or wrong. That is at the core of Bayes' work, called Bayesian inference.
Please see the following article for the Bayesian inference approach and an example of using Bayesian inference to make a job change decision. Bayesian inference is a time-tested belief-updating approach VERY relevant to today’s world. Bayesian inference enables us to make good decisions by understanding our priors and appropriately using new information to update our beliefs. Bayesian inference helps us use our good judgment and overcome our cognitive biases. The Definitive Choice app is presented to implement a Bayesian approach to your day-to-day decision-making.
For an example of using Bayesian inference to help make a decision after a scary terrorist attack, please see the article:
As we discussed near the beginning, Bayesian Inference and Definitive Choice are types of personal algorithms. They implement a robust personal decision process as an outcome of being a good data explorer.
To summarize, the case for being a successful data explorer:
a) data exploration is important in the data abundant / attention scarcity era,
b) data exploration is tricky to manage,
c) data exploration requires a statistical understanding, and
d) data exploration benefits from a robust decision process to appropriately manage.
The rest of the article is an intuitive primer for a core descriptive statistics framework called statistical moments. We start by placing the statistical moments in the context of scientific inquiry. Mathematician William Byers describes science as a continuum. [ii] At one extreme is the science of certainty and at the other extreme is the science of wonder. The statistical moments' grammar rules fall along the science continuum. At the left end of the continuum, the initial statistical moments describe a more certain world. As we go along the continuum from left to right, risk and variability enter the world picture. Then, uncertainty and unknowable fat tails give way to wonder.

The remainder of the article explores the statistical moments, proceeding from the science of certainty and concluding with the science of wonder and managing ignorance.
2. Don't be a blockhead
0th moment: unity
The initial statistical moment 0 describes unity. Unity is a useful opposing comparison for our information and structure-filled lives. Thus, unity describes a lack of information or a world lacking structure. Similar to how black describes an absence of light or color, in a very real sense, unity describes death. Unity helps make the case for why the other statistical moments are so important – since our life is so important.
Unity describes a block of unknown outcomes: Our life has situations lacking certainty but able to be understood with probabilities. These probabilities describe potential differing decision path outcomes, like -- "If I do X, then there are Y different outcomes that could occur. Each Yn outcome path has a unique 'will it happen' probability." Because we have imperfect information and the world is dynamic, the X situation has a set of Y outcomes, including some unknown outcomes. Unity describes the many situations of our life with one thing in common - every situation's outcome probability distribution sums to 100% (or 1). Unity means that, while we may not be able to anticipate a situation’s outcome, something WILL happen. Unity describes the collection of all possible outcome paths found in that block. In the unity state alone, we are unable to differentiate the set of potential outcome paths. They are mushed together like a big blob. Differentiating potential outcomes will come in the later statistical moments.
Earlier in my career, I had a wise boss named Bill Minor. Bill ran a Mortgage and Home Equity operation for a Wells Fargo legacy bank. Bill was famous for saying:
"Not making a decision is a decision."
While Bill may not have been aware of it, he was describing unity. His saying means that regardless of whether or not we make an explicit decision, an outcome is inevitable. In his own special way, my former boss was encouraging me not to be a blockhead.

There is very little fidelity when the situations of our lives appear as a single block of all possible but unknown outcomes. As information, situations appearing as a block of unknown outcomes have no utility born from life's rich diversity. This is the ultimate "only seeing the forest and not the trees" challenge. Unity is at such a high level that all the situation's outcomes, or trees, are jumbled together and only perceived as a single forest. In the unity state, you know the answer or set of answers are somewhere in the big block, you just do not what those outcome answers are.
Unity, like the other moments, has a basis in physics. Unity describes the point of maximum entropy, void of diverse structures necessary to support life. Thus, unity is also a description of not living. As a matter of degree, higher entropy is associated with random disorder that, in a human being, pertains to death. Lower entropy is associated with the order needed to support life's rich diversity.
It may seem strange that order supports diversity. It is our highly ordered cells, neurons, DNA, and related building blocks that make up our skeleton, organs, muscles, and other human structures. It is those highly ordered building blocks that allow our human structure to be so different. Our bodies are made of relatively simple, structured, and homogenous building blocks. It is the astounding volume of those building blocks that enables diversity. Think of our building blocks like a massive tub of Legos. While each Lego may be very similar, an enterprising Lego architect can build virtually anything! In our case, our Lego architect is natural selection as generated from our genome and environment. If it was not for that low entropy building block structure, we would all just be part of the same, undifferentiated higher entropy primordial soup. We will explore diversity more when we walk through the statistical moments following unity.
Unity or high entropy is where all observations share the same random disorder. Concerning the full cycle of life, maximum entropy happens after death and before life, whereas lower entropy is necessary to support life. Religions also make a connection to entropy, unity, and the 0th moment. The Bible makes a case for the 0th statistical moment as the unitary dust composing our existence before we are born and after we pass. Dust is the uniform, high entropy default state from which lower entropy life arises and ultimately returns: "By the sweat of your brow you will eat your food until you return to the ground, since from it you were taken; for dust you are and to dust you will return." - Genesis 3:19
Stoic philosophy describes a similar relationship between the higher entropy state both before we are born and after we die: “‘does death so often test me? Let it do so; I myself have for a long time tested death.’ ‘When?’ you ask. Before I was born.” - Seneca, Epistles 54.4-5
Appreciating the unity described by moment 0 is helped when contrasted with life's rich diversity. Charles Darwin helped the world understand how diversity among the living is ensured by natural selection and genetic mutation. This diversity occurs at conception and birth with the characteristic explosion of life-triggering negative entropy. Thanks Mom! In the other sections, statistical moments 1, 2, 3, and 4 are explored to understand the past reality of our diverse, lower entropy-enabled life.
Going beyond moment 0: Why is diversity important?
It is our diversity that not only enables life but also creates economic prosperity. Our diversity allows people to specialize in various economic activities. Trading the output of our economic specialties enables prosperity. If we were all the same, trading would not be worthwhile. Economist Russ Roberts starkly observes that a lack of trading is contrary to prosperity: "Self-sufficiency is the road to poverty." Money is how we “vote” for the diverse specialties best able to reduce our entropy. Given human life expectancy has more than doubled in the last 200+ years and global economic output (GDP) has increased 50x during that time, our entropy-reducing prosperity has rocketed ahead because of diversity-enabled market economics and the benefits of trade.
The next graphic estimates entropy during life and shows the highest entropy points at the edges of our lives. This is the 0th moment before birth and at death and beyond. Thus, understanding the diversity of our past reality helps us increase prosperity and lowers our entropy during our lives. In general, we seek the lowest levels of entropy during our life. We also seek to maintain those lower levels of entropy for the duration of our life. Statistical moment 0 describes the higher entropy state from which all lower entropy life arises and ultimately returns. Life is the diversity driving our lower entropy.
To explore the impact of entropy across our lives, including the sources for the growth in global economic output, please see the article:

To conclude the unity section, the next graphic shows the resolution for the big block. People have an amazing potential to see through the big block as a set of possible outcomes. [iv-b] We come to understand our outcome paths through the use of the other statistical moments. The language of data and its grammar rules will help you understand your likely paths, identify the potential for risk, uncertainty, and ignorance and get the most out of your life.

For more information on how to manage certainty and uncertainty in our many life situations, please see the HRU framework. The HRU framework is described in the article:
The remaining statistical moments will refer back to "The Big Block" and the four Y outcome types:
Y1 - Known,
Y2 - Risk,
Y3 - Unknown, and
Y4 - Ignorance.
3. Our central tendency attraction
1st moment: the expected value
Next, the first moment measures how a diverse distribution converges toward a central point. This is the simplest description of a diverse population. This is where a known single, solid white path is drawn through the big block. As will be shown in the following Galton Board example, gravity is the great attractor toward the center. There are 3 different central point measures, known as the average. The different average measures are the 'central tendency' descriptors of a distribution - that is - the mean, median, and mode. Each average measure is a little different and their difference gives us clues to consider when applying the remaining moments.
In general, the degree to which the central tendency measures diverge, tells us the degree to which the distribution is not symmetrical. The central tendency measures give us a clue as to how a single distribution compares to the general diverse distribution standard called the "normal distribution." The degree to which central tendency measures diverge describes the degree to which a distribution is or is not normal. However, central tendency measures alone are not sufficient to clarify normality. That is why more grammar of the other statistical moments is needed to more fully describe our past reality.
The normal distribution is a natural standard often used as a comparative baseline between distributions. This standard originates from the physics of calm, natural environments with independently moving molecules and atoms. Normality is that calm, constant-gravity state before excess energy is added to a system. That normal-impacting energy may certainly result from human intervention. Since humans intervene with many systems, we can expect the three average measures to differ.
Is the normal distribution a misnomer? The word 'normal' in "normal distribution" may seem like a misnomer. Since normal distributions are the exception in human affairs, not the rule, perhaps a better name would be the "abnormal distribution" or the "unusually calm distribution."
When considering a distribution, their central tendency measurements should be compared to a) normality, b) each other, and then, c) to the context of that distribution's past reality. These 3 comparisons give us clues to interpreting data the way an artist paints a picture. The tools for an artist are paint and a paintbrush. However, for our intrepid statistical moments language interpreter, their tools are data and statistics. These clues are only a starting point. The clues suggest a line of inquiry involving the other statistical moments.
The data interpreter to artist comparison. The initial title picture shows a window looking out to a mountainous landscape. That landscape is filtered by a black screen covered with data. That data describes the landscape. It is the statistics that help our data interpreter understand that landscape through the data.
Similarly, let’s say our data interpreter was also an artist. They would use paint that represents the colors and textures of what they see in that mountainous landscape. Our data interpreter turned artist will then use the paintbrush to apply that paint to the canvas as their understanding of that landscape.
In this way, data and statistics are just another way for us to interpret our world… like the way an artist interprets the world through their painting.
An example of using the central tendency measurements: Please consider the retirement age of the American population. The retirement population tends to bunch around the mid-60s years of age and then have a long tail toward the end of life - in the mid-80s or beyond. This means most people retire in their 60s, but some wait longer or work to the end of their life. The U.S. Government provides incentives - via social security - enabling retirement in their mid-60s. But not everybody does - or can - retire then. As a result, the mean age will be higher than the median age. This makes sense in the American cultural context. Think of the American retirement culture as a human intervention causing the central tendency measures to differ. But what if we saw a retirement distribution where the mean and median were roughly equivalent? What should be concluded? Relevant questions are:
Is this an American population or perhaps a different culture that does not intervene by relating retirement to not working? In many cultures outside the United States - they either do not have a word for retirement, their definition of retirement relates to change or growth, or retirement means support for people as they age and in their ability to be productive throughout their life. [v]
Perhaps there is a measurement error. Maybe American retirement activities are being improperly recorded as work in the data. Also, the opposite could be true for that initial data set showing the mean-median skew. Perhaps Americans are working after retirement age but their activities are not captured as work. For example, if someone volunteers at a children's hospital, should that activity be considered work? Just because someone does not get paid does not mean that activity does not create economic value on par with paid activities.
If it is an American population, are there context clues as to why the population's central tendency measures are not as expected? Perhaps this is a more agricultural community where retirement age and practices are more tuned to the natural rhythms of the farm. Thus, because there is little government impact, the people's attitudes toward retirement are less dependent on a central government policy and more attuned to life's rhythms.
What is the definition of retirement? Are the 2 datasets using the same definition?
What can the other statistical moments tell us about this population? The other statistical moments will be explored later.
Thus, retirement programs are a social intervention causing less normal distributions. Less normal distributions can be interpreted by using the remaining statistical moments. But first, the normal distribution as a natural standard will be explored with a wonderful simulation. Unlike the retirement distribution, this is where the 3 central tendency measures are the same.
A population simulation - the normal distribution as a natural standard. The Galton Board was invented by Sir Francis Galton (1822-1911) [vi]. It demonstrates how a normal distribution arises from the combination of a large number of random events. Imagine a vertical board with pegs. A ball is dropped on the top peg. There is a 50% chance, based on gravity, that the ball will fall to the right or the left of the peg. The '50% left or right' probability occurs on every peg contacted by the ball as it falls through the board. Think of each peg as representing a simple situation where there are only 2 possible outcomes within the block, left or right. Gravity is the operative natural phenomenon being captured by the Galton Board's design. After many balls are dropped, the result is a normal distribution. More balls are found central than on the outliers of the distribution.
This shows what happens when elements of nature, like atoms or molecules, act independently in a calm, natural system. The outcome often resembles a normal distribution. In the Galton Board, the 'elements of nature' are represented by the balls. The 'natural system' is represented by gravity and the pegs.
Feel free to play with the Galton Board simulation next. Below the box, please activate the "high speed" and "histogram" boxes. Then activate the single arrow to the far left to initiate the simulation. Watch as the Galton Board works its magic. The result is a normal distribution!
Thanks to Wolfgang Christian for this wonderful digital rendering of The Galton Board.
Unlike unity and the dark, undifferentiated big block, we have now added light by drawing a single path through the big block. The average is like the view of a forest as a single entity or path - even though - we know that it is the diversity of trees found in the forest that makes the forest interesting. Perhaps, the fact that the forest's color is usually green or the path through time changes color with the seasons - the average - is interesting to some. The forest’s average does help us understand its dominant attractor. The forest's dominant attractor, as with most natural systems, is gravity. But it has other environmental attractors, like temperature and soil quality. For example, the degree to which there was past volcanic activity will greatly impact the quality of the soil available to the forest’s inhabitants.
However, it is the trees within the forest that possess a diverse array of unexpected colors that are even more interesting. Each species and individual plant develop a nuanced relationship with its environment. Charles Darwin, Natural Selection, genetic mutation, and epigenetics help us understand the great adaptability and resulting diversity of life. Next, we begin our exploration of the diverse trees found in the forest.
4. Diversity by degree
2nd moment: the variance
The second moment helps us understand the distribution’s diversity. The second moment describes the variance of that distribution. That is, how the observations of a distribution differ from its mean. A high variance indicates the population is more diverse than a low variance. In our big block, multiple paths may be drawn through the big block. These are the white, dotted risk lines representing probabilistic outcomes. In our forest and trees example, this is where the tree colors vary in predictable ways from the green color average.
Also, the variance of the population may lead to understanding more uniform subsegments of that population. Back to our forest and trees metaphor – a high variance in the total forest population may lead us to segment the forest by species. Considering the individual species may lead to a lower variance within each species as compared to the forest population in total. The variance of component sub-populations, like tree species, is not necessarily additive to the forest population variance. The sub-populations will also help you understand the species probability as inferred from the forest by tree species. With our knowledge gained from the sub-populations, we can now draw multiple white, dotted lines through the big block. For example: X% Oak + Y% Maple + Z% Cedar + …. n% Other Species = 100%
In the earlier Galton Board example, a normal distribution was demonstrated with a mean, median, and mode of 0. There were an almost equal number of observations above 0 as below 0. However, while many balls landed closer to 0, not all did. In fact, a small number of them fell relatively far from the 0 central point. This variance from the central point occurred because gravity attracted the balls so there was still a 50% chance the ball would fall away from the center of the next peg. As the ball fell away from the center of multiple pegs, the distance from the central point increased. The variance of a distribution, like all statistical moments, can be calculated as a single number. The formula is provided in the links found in the table of contents.
Francis Galton’s work was informed by Adolphe Quetelet (1796-1874). He was one of the founders of using statistics in social science and developed what he called “social physics.” Quetelet's social physics was an attempt to quantify the social sciences in the same way that Newton had quantified physics. Quetelet noticed that social statistics, like crime, stature, weight, etc., fit a normal distribution. Quetelet’s work was pure, in that his social observations were generally independent and occurring in relatively unaffected social environments of his day. This was at a time when there were few social programs or interventions causing a less than normal outcome like in the prior retirement example. In this way, the pure environment was more like how gravity impacts atoms and molecules.
However, often gravity is not the only attractor. As we will explore throughout, human affairs - by definition - will have other attractors. Quetelet's and Galton's work is useful as a gravity-initiated baseline, but in today's complex and policy-impacted world, their work is often insufficient to fully understand most situations alone via the data. The degree to which other attractors impact our past reality is the degree to which our past reality differs from the normal distribution expected value and variance.
Another representation of a variance is a standard deviation. The square root transforms the variance into an easier-to-compare standard deviation. In a normal distribution, about 2/3rds (68%) of the distribution can be found one standard deviation above or below the mean. As such, if 1,000 balls dropped through the Galton Board, about 680 would be within 1 standard deviation of the mean of 0. With approximately 340 being to the left of the mean and 340 falling to the right of the mean.
For some, this may be the only moment to help them understand the world’s diversity. This is unfortunate. The variance alone only suggests a high-level degree of diversity. However, variance does not help describe the essential manner of a population's diversity. That is, the "why" behind the degree to which a variance is higher or lower. In fact, with variance alone, one could conclude the manner of diversity is consistent and well-behaved. As we will discuss next, many systems do not lend themselves to this simplified conclusion.
Well-behaved systems are better described by variance: Sometimes, natural systems are reasonably well-behaved. Think of convection currents available in day-to-day life - such as stirring cream in coffee without a stirrer or defrosting dinner on the kitchen counter. These natural and calm systems are well-behaved. The variance of cream molecules or heat electrons does behave in standard or "normal" ways. Of course, if you stir your coffee with a spoon or microwave your frozen dinner - a human intervention - the excited electrons and molecules will act in less-than-normal ways.

Not well-behaved systems are fooled by variance: This is like people systems, which are notoriously NOT well-behaved. Think of a chaotic stock market. Especially, a stock market after some news event is a catalyst for higher trading volume. Higher trading volume is akin to the higher energy contributing to non-normal distributions. Stock price distributions, especially in shorter time periods, are decidedly not normal. Stock price diversity may reveal unexpectedly large volatility and the volatility may express directional persistence. The traditional variance measure alone, because it fails to describe the manner of diversity, could provide a deceptive view of the stock market.

Many are prone to stopping their past reality investigation at the second moment. Unfortunately, doing so forces us to make inappropriate simplifying assumptions about an extraordinarily complex world. Understanding dynamic stock market systems, like other dynamic systems, require deeper statistical moment investigation than stable coffee stirring systems. In today's world, well-intended social policy creates new attractors diverging from gravity or the well-behaved "pure" environment. It is the third and fourth moment that opens the door to a world teeming with uncertainty and complexity.
For an example of managing volatility in the context of building personal wealth, please see the article:
5. The Pull of the Outliers
3rd moment: the skewness
The third moment is called skewness. It mathematically quantifies inertia by measuring the asymmetry of a distribution, capturing how extreme values (outliers) influence the central tendency and create resistance to change. For example, in a positively skewed distribution, the long tail of higher values creates a pull that shifts the mean upward, reflecting inertia against reverting to symmetry. This property makes skewness a valuable tool for analyzing the dynamics of diverse systems where extreme values drive collective behavior. In the normal distribution introduced earlier, BECAUSE the observations are independent, by definition, there is no inertia. This is because independence implies that each observation is uninfluenced by the others, preventing any cumulative effect or directional pull that might create resistance to change. Without this interdependence, there is no mechanism for momentum or inertia to arise within the system. However, inertia is a regular feature of the diverse distributions of human affairs. Skewness measures the degree to which momentum creates inertia among the observations of a diverse population.
In natural systems and as measured by the normal distribution, the direction set by gravity is the default standard. As introduced in the 1st moment, gravity is also known as an attractor. Because gravity guides (or attracts) the observations toward the default standard, then momentum often causes outcomes to vary from that standard. By the way, 'momentum' and 'inertia' are related but there are some important nuances. Momentum is defined as the tendency of a body to remain in motion. Momentum is the force or speed of an object's movement. In the context of skewness, momentum reflects how a distribution’s asymmetry (caused by extreme values) creates directional motion that influences the central tendency and spreads the data. For example, in financial markets, momentum from repeated behaviors like herding leads to skewness, as successive actions amplify deviations from the norm. Inertia is defined as the tendency of an object to oppose the change in its position.
In human affairs, individuals have different kinds of attractors. In our day-to-day lives, it is the legal environment, culture, and our social connections creating a momentum guiding us toward varying outcomes. The social attractor is a powerful alternative attractor that may inappropriately impact our decisions. It does not mean those outcomes are guaranteed, but those environmental factors relentlessly attract our lives. This is like the relentlessness conjured by the aphorism: "Water finds it own level."
In terms of the important decisions of our lives:
a) people are strong social creatures and tend to herd together when making decisions, and
b) most significant decisions have uncertainty.
The power of our social nature should not be underestimated as an inertia-generating force. Sociologist Brooke Harrington said that if there was an E=MC^2 [energy equals mass times the square of the speed of light, Einstein's Equation] of Social Science, it would be that the fear of social death is greater than the fear of physical death. [vii]
This means if your social reputation is on the line (a) and you have financial decisions laced with uncertainty (b), you are more likely to follow social cues – even if those social cues lead to a worse outcome for you. An example of the “social death > physical death” fear phenomenon is our nature to sell investments into falling stock markets. This behavior contributes to measurable skewness in stock market data by creating asymmetry in price movements. When large groups of investors sell in response to falling markets, they amplify downward momentum, shifting the distribution of returns and causing a longer tail on the negative side. This herding behavior reinforces the skewness, making market recovery slower and more challenging. Even though, financial theory and centuries of experience tell us buying diversified investments in falling markets is the best approach to maximizing wealth.
So, the gap created by an individual's uncertainty is often filled by our social nature to follow others. As a result, an individual's observations are likely to attract followers. It is the followers' herding behavior that creates inertia. It is this herding behavior that skewness measures. For example, stock prices often generate momentum and cause inertia as measured by skewness. In recessionary economic environments, stock prices tend to get downward momentum. People tend to follow the persistent stock selling of others by their own selling. If people were “normal” – meaning we act like the balls falling on the Galton Board – then inertia would not exist and stock prices would not gain skewness-causing momentum. But people are not normal! At least from a statistical sense.
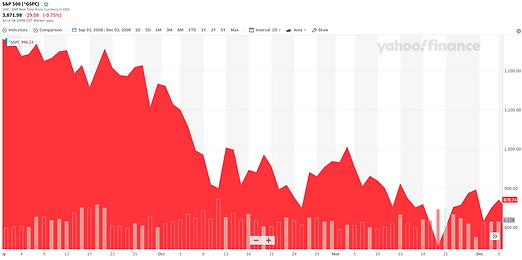
The S&P 500 from September 1 to December 1, 2008. This demonstrates an almost 40% drop during the "dark days" of the Financial Crisis.
In expanding economic environments, the opposite occurs. Stock prices tend to get upward momentum - people tend to follow the persistent buying of others with buying of their own. Financial experts know inertia can be destructive to an individual’s wealth. Objectively, a wealth-generating habit is for people to "buy low and sell high." However, our nature is to "buy high and sell low," especially in chaotic, sell-off markets. This wealth-preventing perversion is part and parcel of social inertia found in the 3rd moment. These inertial patterns persist and the human nature from fear and herding often overrules objectivity. Arguably, the single most important contribution of behavioral economists is the 'commitment device.' This device helps people overcome their human nature when skewness and momentum lead to inertia and poor outcomes.
The S&P 500 for the decade beginning September 2008. This demonstrates an over 120% gain including and after the Financial Crisis.

Please see the next link to explore the mathematical intuition of the time value of money and why overcoming inertia is critical to long-term wealth.
Please follow the next link for an example of a commitment device in action. The commitment device is explored in section 3, "Pay Yourself First."
6. The tale of tails
4th moment: the kurtosis
The fourth moment is called kurtosis. Before jumping into kurtosis, let's summarize how we got here. As found in the previous moments, our attention has been drawn toward the center of the distribution. However, each subsequent moment has been steadily moving away from that center. While the earliest moments accept the world as more certain, the last two moments acknowledge the volatility inevitably present in our lives.
Kurtosis has the opposite attention focal point. We will now focus on the tails or outliers of those distributions. As we will discover, the way of thinking in the tails is VERY DIFFERENT than the thinking in the center. Kurtosis, or 'thickness of tails,' helps us understand the degree to which uncertainty impacts a distribution. In our big block, multiple unknown paths exist in the big block. These are the dark, solid uncertainty lines representing unknown outcomes.
Human systems typically have ‘fat tail’ distributions indicating that uncertainty is even more prevalent than in normal tails. Fatter tails occur because the human system's central tendency attractors include many other attractors besides gravity. Tail thickness is indicated by kurtosis. This is why traditional risk measures, often relying on an assumption of normality, do not work well in typically dynamic systems. The great financial crisis of 2008-09 is an example. The compounding complexities of the environment led to loss outcomes not anticipated in the normal space. It was the layering of dynamic risks and exponential growth leading to losses only predictable in the context of thick tails and excess kurtosis. Nicholas Nassim Taleb is an author, researcher, former bond trader, and expert on fat tails. He offers a cautionary suggestion for kurtosis:
"Everything in empirical science is based on the law of large numbers. Remember that it fails under fat tails." - N.N Taleb
Excess kurtosis means that large losses, such as a massive sell-off in the stock market or massive, longer-term drops in home prices are more possible than a normal view of the world suggests. But it is not just losses, great unexpected gains may be achieved from excess kurtosis. As we will explore, kurtosis is agnostic to the quality of the outcome, whether a loss or a gain. Exponential growth and general convex functions are common to the transformation of many distributions, including distributions with excess kurtosis. An example of a convex function is the time value of money associated with personal finance. But many other convex functions are impacting our lives - such as health and longevity. The degree of kurtosis exposure is agnostic to outcomes of convex function transformations - which means outcomes can be good or bad.
Convex functions in the context of personal finance. Convexity has a specific, bounded usage in personal finance.
1) Shape and space – The modeled time value of money function is “convex to time.” This means it increases at an increasing rate in positive time and positive outcome value space. A personal finance application convex to time cannot go negative to time. Also, over the long run of multiple business cycles, consistent investing, and a properly diversified portfolio, the function will not go negative to outcome value.
2) Volatility management – In the long run, there is an equal chance of positive or negative volatility occurring in the short term. The time value of money function is “convex to time” and exposed to this stochastic volatility. As such, the portfolio holder will benefit more from upside volatility than downside volatility in the long run. N.N Taleb coined the term “antifragile,” in the book by the same name, to represent this investment outcome.
Please see a discussion of Jensen's Inequality to demonstrate convex functions and how it is applied to personal finance.
Manage your Fat Tails

The idea is to expose yourself to convex functions in a way that increases the chances of good outcomes and minimizes the chances of bad outcomes, regardless of the tail thickness. All the while, protecting oneself from ruin. The best way to achieve good outcomes is to make sure ruin does not prevent you from playing the game enabling that good outcome.
Think of healthy personal habits and saving for retirement as ways to expose yourself to convex functions that drive good outcomes. These good outcomes may be benefited by thick tails. Think of high deductible health insurance as protection from a bad outcome and automated savings as contributors to a good outcome. A properly protected convex function is more likely to benefit from thick-tailed distributions. For example, if the stock market has thick-tailed volatility and the investor:
Has a long investment time frame,
Diversification to protect from fat tail-based ruin, and
Makes regular investment contributions,
The investor WILL benefit more from exposure to volatility and the upside of fat-tail volatility than suffer losses from the downside.
Please see the article to explore practical convex function applications:

Managing thick tails is very different than managing central tendencies. Consider ruinous events, such as a house fire or cancer. By our behaviors - like safety, exercise, and healthy eating - we can reduce the chance of those fat tail events. But they do happen. This is why insurance - like high deductible health insurance or fire insurance - is a great ally to manage your fat tails.
High deductible insurance has 2 benefits, with the second being more powerful than the first:
High deductible insurance will cover the top-end risk of some ruinous event. High-deductible insurance is generally less costly than lower-deductible policies. One is usually better off saving for some loss event beneath the higher deductible policy than insuring it with a low deductible policy.
Since high deductible insurance does not cover less costly events below the high deductible - the insured still has skin in the game. Thus, high deductible insurance keeps the insured focused on behaviors reducing the chance of that fat-tail event from occurring in the first place. This is called "de-moral hazarding." The next video provides additional de-moral hazarding context.
In the U.S. especially, high deductible insurance purchased outside an employer has a third benefit. Making insurance portable makes it easier to change employers. This uses the same reasoning as 401(k)s and pensions for retirement. 401(k)s, by definition, are portable and make it easier to change employers. For health insurance, employers have the option to contribute to tax-benefited accounts called Health Reimbursement Arrangements or HRAs. This allows an employer to provide funding for employees to purchase health insurance plans on the ACA website.
Managing risk is different than managing ruin. Risk is considered through probabilities, central tendencies, and expected outcomes. Risk can be objectively managed with the help of the law of large numbers. Risk management planning will direct resources to lessen or eliminate risk severity - should a risk be realized.
Ruin, on the other hand, is to be avoided. Ruin is an end point - there are no do-overs. Ruin is managed via the "law of small numbers." Since ruin lives in the tails of uncertain distributions, the first three moments are less helpful. Insurance and personal behaviors to handle potentially ruinous events are essential.
Fat tails and de-moral hazarding - a banking example:
In the world of banking, large banks depend on taxpayer bailouts to protect from ruinous events. Fiscal stimulus programs associated with the financial crisis and the pandemic are bailout examples.
For example, Robert Rubin is the former CEO of Citibank. He was the CEO before and during the financial crisis. Rubin became very wealthy as the CEO, in part, because he made outsized banking bets before the crisis. Those bets exposed Citibank to the risks leading to the financial crisis. U.S. taxpayers bailed out Citibank and Rubin. Rubin kept all the compensation he earned while guiding Citibank to take those banking systems existential risks. Unfortunately, banks do not get the skin in the game advantage of de-moral hazarding. Perhaps society would be better off if they did.
In an interview with Business Insider writer Matthew Boesler, N.N. Taleb said:
“Nobody on this planet represents more vividly the scam of the banking industry,” says Nassim Nicholas Taleb, author of The Black Swan. “He [Robert Rubin] made $120 million from Citibank, which was technically insolvent. And now we, the taxpayers, are paying for it.”
To be fair, Taleb is picking on Mr. Rubin. Pretty much all senior operating executives from large banks could be called out for their lemming-like competitive behavior and how they profited leading up to the financial crisis. These senior executives could fairly claim they were just doing their best given the environment of the time. History will judge whether their claims are fair or not.
Please see the article to explore fat tails and the difference between risk and ruin. The article is presented in the context of entropy's operational cousin, known as 'ergodicity:'

Finding the unknown: The big block shows the “unknown, unknown” as a dark line. This means those unknowns exist but we do not know where they are. Economist Russell Roberts defines the problem well when he says: “By focusing on what you know and about what you can imagine, you’re ignoring the full range of choices open to you.” [viii] Also, Thomas Schelling said: “There is a tendency in our planning to confuse the unfamiliar with the improbable.” [ix] So, what do we do about it!? How do we find the unknown, unknown, when, well, it is unknown?
In a word, the answer points us toward actively engaging with serendipity. According to Merriam-Webster’s dictionary, serendipity is “the faculty or phenomenon of finding valuable or agreeable things not sought for.” Earlier, N.N. Taleb was introduced. As an example, Taleb suggests one of his favorite pastimes is "flaneuring," which is his way of exposing himself to the convexity benefits of serendipity. Thus, flaneuring is an input to the serendipity convex transformation function. This is just like savings are an input to the time value of money convex transformation function and healthy habits are an input to our long-term health convex transformation function.
Flaneuring is purposely exposing oneself to an environment where a positive unknown may be uncovered. A serendipitous outcome of flaneuring is when understanding from a former unknown (Y3) is moved to one of the known paths (Y1 or Y2). I do this by being around people or situations I am unfamiliar with - but hope they could have something interesting to share. Attitude is important. While I purposefully seek to engage in serendipitous environments, I do not pressure the environment with high expectations. However, after every encounter, I am careful to self-debrief and capture the cool stuff I gleaned from the encounter. The 'de-brief and glean' is that essential step of capturing heretofore unknown data. This is a potential starting point for moving from the unknown (Y3) path.
My work as the curator of The Curiosity Vine provides these opportunities. I have had many interesting discussions with potential idea incubators. Not all of them turn into something “known.” But all the conversations add value to the “unknown” that may someday, move into a “known” path on my big block. Also, I consider these interactive discussions as symbiotic. That is, I am learning from someone's known Y1 or Y2 path, at least part of which may be found on my unknown Y3 path. The opposite occurs, I share from my known Y1 or Y2 path to potentially inform their unknown Y3 path.
It takes a bit of faith to invest in something that has no short-term, measurable return. It takes an open mind to discuss something that is far afield from what is known. The good news is, I can flaneur on the side. While I spend most of my time on the known (Y1) or managing the risk (Y2) paths found in the big block, I consistently make time for achieving serendipity found in the unknown (Y3). Honestly, I wish I could spend more time on the unknown. It is incredibly interesting and a source for feeding my voracious curiosity.
For an example of a successful idea incubation and moving the unknown Y3 path to the known Y1 and Y2 paths, please see:
The unknown as a path to innovation: Dealing with uncertainty, or the "unknown, unknown," is an area of intelligence that is uniquely human and has a comparative advantage relative to artificial intelligence.
“What is now proved was once only imagined.“
- William Blake (1757 - 1827)
Why? The known and risk paths are the domain of artificial intelligence. These are paths that are informed by data. Artificial intelligence is far better at assimilating and organizing massive stores of data than humans. However, AI can only provide a forecasted outcome in the context of the data it is trained upon. It is the unknown that, by definition, is void of data. It is the human ability to deal with counterfactuals and apply intuition and creativity that makes us uniquely able to handle the unknown. This is the domain of innovation.
Most innovators seek the Y3 or the unknown, unknown path. They are motivated to uncover improvements to the existing world by providing solutions to challenges not already known. Innovators start by building a deep understanding of the known (Y1 and Y2) and understanding the gap between that known and what could be (Y3). They seek to bridge that gap with some invention or related new approach. The invention or new approach is only part of the solution. It is the innovator, via using a trial and error process, that creates new data in the service of closing the gap from the unknown to the known. The magic of building new data and moving from the unknown to the known comes from this innovation process.
Updating beliefs helps uncover the unknown: Serendipity and innovation have been discussed as approaches to uncovering the unknown. But there is a deeper question of how to encourage serendipity and innovation. Earlier, we intoduced the nimble decision-maker in a video. Central to being a nimble decision-maker is belief updating. Albert Einstein said:
“Whether or not you can observe a thing depends upon the theory you use. It is the theory which decides what can be observed.”
This is an incredible observation made long before the existence of AI and the systematic collection of data. An AI does not need theory. It predicts the future based on the data it can see. However, it is the unseen that is often necessary to accurately predict the future.
Einstein’s saying suggests that our unknown Y3 path may be uncovered by changing our theory. This is like looking under rocks we did not know were there. Also, as discussed in the introduction, our theory or perspective is greatly variable. Our own perspective is likely different than others and even our own perspective is impacted by time and the situation. Variability, how we sample, and the influence of cognitive biases will impact how we form beliefs. Being aware of and actively engaging our natural variability is part of innovation.
This is why being clear about your own benefit model and updating that model is so important. Earlier, personal algorithms and choice architecture were introduced. Beliefs are impacted by the quality of our personal algorithms. We may actively impact these beliefs by our willingness to proactively uncover the Y3 unknown path.
Some may believe the goal is to find and fix a belief they can consistently rely upon. Our goal is different. To capture our uniquely human comparative advantage, the revised goal is to:
Recognize the world is so dynamic that fixing beliefs is not advisable.
Current beliefs are like temporary weigh stations on the journey to uncover the ever-changing Y3 unknown paths.
The better goal is to grow your decision process to consistently consider, test, and update beliefs. The human comparative advantage to AI is that we can imagine counterfactual but plausible worlds and then create unique data to test that imagined world.
Belief updating is an evolutionary process, where new, environmentally tested ideas are grown and old, environmentally fragile ideas contract.
In the context of innovation, new or revised beliefs may be considered as a set of possibilities needing to be tested.
7. Fooling ourselves
A moment of ignorance
To finish the big block path discussion introduced earlier, please note the fourth Y4 ignorance path found at the bottom of the big block graphic. This is where we thought a path was known – either the white solid or white dotted line – but turns out to be something different. As explored via the following HRU framework, the "unknown, known" of ignorance is generally a worse state than the "unknown, unknown" of uncertainty.
This is because we fooled ourselves, at the time a decision needed to be made, into considering a belief to be in the known outcome category. Ultimately, upon a post-mortem inspection, we determined we made a mistake about the potential outcome. It becomes clear that the outcome was knowable but we failed to properly assess the data at that decision moment. As a point of clarification, the reasoning error is more likely to be an error of omission. That is, the data was either unavailable, ignored, or mis-weighted as needed to make a better assessment. "Fooling ourselves" relates to the trope:
"It seemed like a good idea at the time."
At least when something is on the Y3 unknown path, we can still use our belief-updating process to inform and update that belief. Also, as in the case of the Y2 risk path, we knew something was possible and the probability that it may or may not happen. However, in a state of ignorance, as found on the Y4 path, we do not even know that a belief should be updated or considered a risk. "It seemed like a good idea at the time" is often an expression of regret for not updating a belief to better impact an outcome.
The next graphic describes the "The Big Block's" four Y outcome types. We describe those 4 paths along 2 time-based dimensions:
Situation or what we know today
Outcome or what the uncertain future holds.
As a reminder, those four Y outcome types are:
Y1 - Known - or the "Happy Place" starting point,
Y2 - Risk,
Y3 - Unknown, and
Y4 - Ignorance.

For more information on how to manage certainty and uncertainty in our many life situations, please see the HRU framework. The HRU framework is described in the article:
"Fooling ourselves" with ignorance is common and occurs because of a lack of belief updating. Ignorance is the outcome of persistent confirmation bias. Reducing ignorance is the clarion call for understanding your data and having a robust belief updating process. Reducing ignorance is served by having a consistent, repeatable decision process. Earlier, the Definitive Choice app and a Bayesian approach were suggested to implement the best day-to-day decision-making process.
Why is ignorance common and a big challenge? Ignorance, or the “unknown, known” is a feature of our neurobiology. You saw that correctly – “ignorance is a feature!” Our brain’s ability to update evidence and knowledge takes work. Whereas, our fast-brain-oriented responses occur based on the habits presented from existing evidence and knowledge. If a lion is bearing down on you, our slow-brain-oriented response is to calculate the proper exit direction and speed. Whereas our fast brain response is to "run, now!" Naturally, our evolutionary response is to respond to our fast brain and avoid being a lion snack.
It takes work to update evidence, knowledge, and resulting beliefs - it is much easier to react to existing beliefs formed from existing memories. Memory is based on an existing network of neurons and synapses. The strength of that memory is based on the number of neurons and both the number and size of those synaptic connections forming that memory. The more and bigger the neurons and synapses, the stronger the memory and corresponding habits. That is why a strong habit is so challenging to change, a habit “feels” normal, regardless of whether it is a good habit or not.
But here is the thing, existing memories create inertia. So, if you have a “known, known” that evolves to an ignorant “unknown, known” you are much less likely to perceive it as an ignorance signal in need of updating because your habits are still relying on your old "feel good" memories to support a belief. Belief inertia is at the core of confirmation bias. That is why having a robust belief updating process, especially in the data abundance era, is so important!
"The Fast Brain" and the human ability to forecast were discussed earlier and cited with Our Brain Model. The "high emotion tag & low language case" is related to those habits providing fast access to memories but also belief inertia potentially leading to ignorance. The "low emotion tag & high language case" is related to the slower updating process necessary to change or reinforce those habits.
To be clear, it is not that ignorance should be avoided at all costs. There is a difference between the temporary ignorance associated with learning and the persistent ignorance associated with confirmation bias. Part of learning is trying new stuff and doing as well as we can. You may think you know something about an outcome and want to give it a try. When there is an unknown, 'giving it a try' is code for testing and creating data to update our outcome path understanding from the Y3 unknown path to a Y1 or Y2 known path. However, getting stuck in those outcome beliefs and not updating is the ignorance we should strive to avoid. The new data may suggest your tested belief was wrong. Being a good data explorer is about properly introducing outside-in data and updating as we learn.
There is an old saying that encourages people to try things, even if they do not have the skills or data YET to be successful at that thing:
"Fake it till you make it"
This an aphorism encouraging the projection of confidence, competence, and an optimistic mindset to achieve the desired results. It involves consciously cultivating an attitude, feeling, or perception of competence that you don't currently have by pretending you do until it becomes true. This is a great way to cultivate habits to achieve an aspirational objective.
I like the aphorism but also believe that aphorism has the potential to devolve into ignorance. What if that aspirational objective devolves to be inaccurate? Following a belief updating process will help you know whether or when to stop faking and cut bait. In the next example, we will demonstrate how habits begun in liberty devolved into the death of Americans at American hands.
January 6th, 2021, an ignorance example: Consider the highly sensitive matter of the January 6, 2021 storming of the U.S. Capitol. This attack resulted in the death of Americans at American hands. As stated in the U.S. Congressional Committee investigation report: [x]
“The Committee’s investigation has identified many individuals involved in January 6th who were provoked to act by false information about the 2020 election repeatedly reinforced by legacy and social media.”
This has all the markings of confirmation bias and both errors of commission and errors of omission. The attackers believed, and may still believe, the attack and killings were justified.
As revealed by the investigation, the attackers did not subtract false data - an error of commission - and ignored or underweighted moderating information - an error of omission. This is a classic decision-making challenge. At this point, the reader may feel that suggesting the January 6th attackers were impacted by ignorance seems judgmental. Fair enough. For this example, the author’s perspective is generally based on American law and cultural expectations:
1. Do Americans have the right to protest? - YES, of course!
2. Do Americans have the right to kill or maim while protesting? - NO, of course not!
3. Do Americans have the responsibility to curate data and weigh all the facts? YES!
Perhaps, if the January 6th attackers had spent more time curating data and inspecting their beliefs, the outcome would have been different.
When evaluating a new situation, be on the lookout for those decision inputs that may be a deal killer. This means that if there is something that is a necessary input to the decision and not completing it would ruin the decision, then be hyper-focused on managing that risk to the desired outcome. Either eliminate that risk or quickly "kill the deal" if the risk is unable to be eliminated. Salespeople sometimes call deal killers "Fast to No." This is used when pursuing a possible sales lead. If the sales lead is not going to pan out, a good salesperson will quickly "kill the deal" by prioritizing other leads. Unfortunately, these kinds of deal killers sometimes get ignored longer than they should. This is a source of ignorance.
Good salespeople also know that deal killers may change over time. So, perhaps they "kill the deal" today, but they seek to maintain a relationship with those parties from the killed deal. If the environment changes and that "necessary something" changes to be viable, then they will "unkill the deal" and seek the beneficial outcome.
The Monkey and the Pedestal is a fun parable to help remember to focus on deal killer risks.
You want to get a monkey to recite Shakespeare while sitting on a pedestal. What do you do first? Train the monkey or build the pedestal? It’s obvious that training the monkey is a much harder task, and it’s quite likely that we are tempted to start with sculpting a beautiful pedestal instead. But if we can’t get the monkey to recite the monologues on the ground, then all the time and energy put into crafting the pedestal are wasted.
- Astro Teller, the head of X, Google's moonshot division
Systemic bias: Up to this point, it has been shared how data, or our past reality, may be understood via the language of statistics. Systemic bias is different. This is where you could be fooled into believing the data represents our past reality when, in fact, the data becomes more deceiving than helpful. Supporting this point, the late Harvard scientist and system researcher Donella Meadows said:
“…. most of what goes wrong in systems goes wrong because of biased, late, or missing information.”
Systemic bias, also known as structural bias, is another sink for ignorance. This is where the data itself may lead to an inaccurate conclusion. Earlier, we discussed Sir Francis Galton and his contribution to statistics and the normal distribution. In the notes section, we explore how Galton leveraged the language of statistics, a variant that he called 'eugenics,' to further his and his contemporary's racist beliefs. As a counterpoint to Galton's misguided use of statistics, Nobel laureate F.A. Hayek coined the word “scientism” to mean:
“not only an intellectual mistake but also a moral and political problem, because it assumes that a perfected social science would be able to rationally plan social order.” [xi]
It is that scientistic assumption - "a perfected social science would be able to rationally plan social order” - that is more likely to lead to a systemically biased outcome. This was certainly the case in Galton's eugenic applications of statistics. [xii]
Systemic bias leads to systemic discrimination. Systemic discrimination is a form of institutional discrimination impacting economic agents, such as race or gender, which has the effect of restricting their opportunities. It may be either intentional or unintentional, and it may involve either public or private institutional policies. Such discrimination occurs when policies or procedures of these organizations have disproportionately negative effects on the opportunities of certain social groups.
The theory of structural discrimination is generally researched by sociologists. Systemic discrimination is also known as structural discrimination.
Specific to home ownership and mortgage lending, please see this home appraisal bias as an example of structural bias.
This may seem discouraging. Even data may be less than complete or even incorrect. In the world of data abundance, this is a reality. However, the enemy is not data. Data simply represents our past reality. I hope that the fear of ignorance will motivate you to increase your focus on being a good data explorer. As we discussed in the introductory section, the hunt should be to better understand the grammar rules, so we can:
Learn from our past reality,
Update our beliefs, and
Make confidence-inspired decisions for our future.
I encourage you to be an active data curator, be on the lookout for systemic bias, and update your beliefs when you learn something new. As you become a better data explorer, the chances of being fooled by ignorance will decrease.
To further explore challenges in the data-abundant era, please see the article:
To further explore being a data curator, please see the article:
Before we conclude
Like life, the wind blows in unexpected ways. The next wind metaphor walks through how the volatile and unforeseen winds of life impact our statistical moments. The metaphor addresses how different attractors impact the statistical moments with a Galton Board thought experiment:
Earlier, the Galton Board was presented as a visualization of how a normal distribution is formed. This assumes a calm environment, where the observations (balls) are independent and where constant gravity is the only attractor or energy source. Now, what happens if we add a fan and the wind it generates is like an alternative "human intervention" attractor? Will the wind impact how the balls fall through the Galton Board and the resulting distribution? You bet it will!
The Expected Value (average) - Statistical moment 1: The wind may impact the 3 central tendency measures. For example, if the wind blows from left to right - known as a left-skewed or negative skewness.
Moment 1 outcome: The median will likely be higher than the mean.
Variance - Statistical moment 2: What if the wind blows from the top and pushes balls out toward each tail?
Moment 2 outcome: The variance increases.
Skewness - Statistical moment 3: What if the wind blows from left to right?
Moment 3 outcome: The skewness increases.
Kurtosis - Statistical moment 4: What if the wind blows intermittently, from both directions?
Moment 4 outcome: Excess kurtosis occurs.
Ignorance - A moment to change: What if the wind blows from left to right and we make an inference? Then the wind direction changes to blow from right to left?
Potential ignorance outcome: This is when we should update our wind direction priors and assess changing our minds. If not, we are more likely to suffer ignorance.
Please see this video for a wind-capturing adaptability perspective from Standford University Entrepreneurship Professor Tina Seelig and Venture Capitalist Natalie Fratto.
8. Conclusion
Just like grammar rules for language, statistical moments are essential for understanding and capturing the entropy-reducing benefits accrued from our past reality. And, just like grammar rules for language, statistical moments take practice. This practice leads to the effective understanding of our past reality and for statistical moments to become a permanent feature for your information-era success. Data, as representing our past reality, contains nuance and exceptions adding context to that historical understanding. Also, there are even more grammar rules that help guide us in more unique circumstances. Building statistical intuition is your superpower in the Information Age. As Gene Roddenberry said:
"The effort yields its own rewards."
Data provides a map of our past reality. The better we understand the statistical language of data, then, the better we will understand our past reality to enable our belief updating. But the map is not the terrain, just like a Google map is not the same as the dynamic natural world it represents. It is important not to confuse representation with reality. Dynamic systems always have uncertainty. No matter how well we learn statistical moments, we must respect the inevitable unknowns of all situations. We should seek to understand and minimize ignorance. The statistician George Box said:
"All models are wrong, but some are useful."
Thus, understanding how to make data-informed models of our past reality useful is essential for our data-abundant world. In the introduction, we introduced ‘being Bayesian’ as an important concept for making the best decisions. Using tools like Definitive Choice is very helpful for implementing the Bayesian approach.
More examples and context are found in the article:
For a framework and a pet purchase example for productively leveraging consumer product company's AI and algorithms in the average customer's life, please see the article:
Appendix - How well are algorithms aligned to you?
This appendix supports the "This article is about data, not algorithms" disclaimer found at the end of the introduction.
Generally, public companies have 4 major stakeholders or "bosses to please" and you - the customer - are only one of the bosses. Those stakeholders are:
The shareholders,
The customers (YOU),
The employees, and
The communities in which they work and serve.
Company management makes trade-off decisions to please the unique needs of these stakeholder groups. In general, available capital for these stakeholders is a zero-sum game. For example, if you give an employee a raise, these are funds that could have gone to shareholder profit or one of the other stakeholders.
This means the unweighted organizational investment and attention for your customer benefit is one in four or 25%. The customer weight could certainly be below 25%, especially during earnings season. Objectively, given the competing interests and tradeoffs, this means a commercial organization's algorithms are not explicitly aligned with customer welfare. Often, the organization's misaligned algorithm behavior is obscured from view. This obscuring is often facilitated by the organization's marketing department. Why do you think Amazon's brand image is a happy smiley face :) For more context on large consumer brands and their use of algorithms please see the next article's section 5 called "Big consumer brands provide choice architecture designed for their own self-interests."
The focus on data will help you make algorithms useful to you and identify those algorithms and organizations that are not as helpful. Understanding your data in the service of an effective decision process is the starting point for making data and algorithms useful.
While the focus is on the data, please see the next article links for more context on algorithms:
An approach to determine algorithm and organizational alignment in the Information Age:
How credit and lending use color-blind algorithms but accelerate systemic bias found in the data:
Notes and a word about citations
Citations: There are many, many references supporting this article. Truly, the author stands on the shoulders of giants! This article is a summarization of the author's earlier articles. Many of the citations for this article are found in the linked supporting articles provided throughout. I encourage the reader to click through and discover the work of those giants.
[i-a] Wansink, Sobal, Mindless Eating: The 200 Daily Food Decisions We Overlook, Environment and Behavior, 2007
Reill, A Simple Way to Make Better Decisions, Harvard Business Review, 2023
[i-b] The challenge of how high school math is taught in the information age is well known. The good news is that it is recognized that the traditional, industrial age-based high school "math sandwich" of algebra, geometry, trigonometry, and calculus is not as relevant as it used to be. Whereas information age-based data science and statistics have dramatically increased in relevance and necessity. The curriculum debate comes down to purpose and weight.
Purpose: If the purpose of high school is to a) prepare students for entrance to prestigious colleges requiring the math sandwich, then the math sandwich may be more relevant. If the purpose of high school is to b) provide general mathematical intuition to be successful in the information age, then the math sandwich is much less relevant. I argue the purpose of high school for students should be b, with perhaps an option to add a for a small minority of students. Also, it is not clear whether going beyond a should be taught in high school or be part of the general college education curriculum or other post-secondary curriculum. Today, the math sandwich curriculum alone lacks relevance for most high schoolers. As many educators appreciate, anything that lacks relevance will likely lead to not learning it.
Weight: Certainly, the basics of math are necessary to be successful in statistics or data science. To be successful in b) one must have a grounding in a). The reality is, high school has a fixed 8-semester time limit. Which, by the way, education entrepreneurs like Sal Khan of Khan Academy argue against tying mastery to a fixed time period. But, for now, let's assume the 'tyranny of the semester' must be obeyed. As such, the courses that are taught must be weighed within the fixed time budget. Then, the practical question is this: "If statistics and data science become required in high school, which course comes out?" I suggest the math sandwich curriculum get condensed to 4 to 5 semesters, with the information age curriculum being emphasized in 3 to 4 semesters.
The tyranny of the semester can be overcome with education platforms like Kahn Academy. Since the high school math curriculum increasingly lacks relevance, an enterprising learner or their family can take matters into their own hands. Use Kahn Academy outside of regular class to learn the data science and statistics-related classes you actually need to be successful in the information era.
[i-c] Upton Sinclair’s aphorism, "It is difficult to get a man to understand something, when his salary depends on his not understanding it." was suggested as why education system curriculum administrators will not lead the charge in updating older, industrial era math curriculum to the needs of the information age.
First, there is no doubt that there are many well-meaning and talented people administering education curricula. The challenge is one of incentives in terms of the administrator’s skills and the system itself. The best way to understand this challenge is with a home-building metaphor.
In the home building business, sometimes it makes more sense to tear down a house to its foundation than try to do a home improvement to the existing house. This is because:
The current house, while well built for the time, is now significantly out of style from current expectations. Perhaps today, people want more square footage, higher ceilings, more open floor plans, etc. These are significant changes to the current home.
The value of the land under the house is relatively high. In order to get the most out of the land value, the existing land improvement - or house- needs to be adjusted. Effectively, to get the most out of the environment -the land, how that environment is engaged - the house - needs to be changed.
The cost of a home improvement would be higher than tearing it down and building it from scratch.
Now, let’s apply this thinking to the curriculum administrator. The curriculum administers the high-value education system environment to provide the next generation of human capital. The curriculum administrator has built their career and commanded a higher salary by managing the industrial era curriculum. The administrator desires to tweak the curriculum to fit it into the industrial-era curriculum system they administer. However, the drastic changes to the curriculum needed are like a tear-down. The curriculum administrator's fear, whether accurate or not, is this: Once torn down, the curriculum administrator’s skills, geared toward the old curriculum approach, may not be as needed. Or, if needed, those skills will not be needed at the salary level they had formerly commanded.
Thus, the industrial era curriculum administrator’s incentives will naturally lead them to resist a curriculum ‘tear-down.’
[ii] Byers, The Blind Spot: Science and the Crisis of Uncertainty, 2011
[iii] Kahneman, Slovic, Tversky (eds), Judgement under uncertainty: Heuristics and biases, 1982
[iv] See Our Brain Model to explore 1) the parts of the brain lacking language, called the fast brain, and 2) people’s abilities to see through the big block.
a) The Fast Brain: The human ability to quickly process information through our emotions is anchored in the right hemispheric attention center of our brain. Please see the “The high emotion tag & low language case” for an example.
b) The Big Block: The human ability to forecast the future based on past inputs is anchored in the left hemispheric attention center of our brain. Please see the “The low emotion tag & high language case” for an example.
Hulett, Our Brain Model, The Curiosity Vine, 2020
[v] Luborsky, LaBlanc, Cross-cultural perspectives on the concept of retirement: An analytic redefinition, Journal of Cross-Cultural Gerontology, 2003
[vi] Francis Galton was a hardcore racist. To be fair, in the day, racism was commonly accepted as was the belief that certain races of people were naturally superior to others. However, he used his brilliant statistical insights to create an infrastructure of human discrimination called Eugenics. Among other uses, a) the Nazis used Galton’s ideas to support their genocide and b) the United States used Eugenics extensively. Many states had laws allowing "state institutions to operate on individuals to prevent the conception of what were believed to be genetically inferior children." The author is abhorred and saddened by Galton’s attitude, the general attitudes of the day, and the uses of Eugenics. However, the author does find Galton’s statistical research and development very useful. As well as the Galton Board is a very helpful explanatory tool for the normal distribution. History is replete with people with misguided motivations, as judged by history, but that created useful tools or technologies for future generations.
Another interesting historical note, Galton is a blood relative – a younger half-cousin - of Charles Darwin. The story goes that Galton was driven by family rivalry to make his own historical name.
Editors, Eugenics and Scientific Racism, National Human Genome Research Institute, last updated, 2022
[vii] Roberts (host), David McRaney on How Minds Change, EconTalks Podcast, 2022
[viii] Roberts, Wild Problems: A Guide To The Decisions That Define Us, 2022
[ix] Wohlstetter, Pearl Harbor: Warning and Decision, 1962
[x] Congressional Committee Members, final Report Select Committee to Investigate the January 6th Attack on the United States Capitol, 117th Congress Second Session House Report 117-663, December 22, 2022, https://www.govinfo.gov/content/pkg/GPO-J6-REPORT/pdf/GPO-J6-REPORT.pdf.
[xi] Editors, Hayek and the Problem of Scientific Knowledge, Liberty Fund, accessed 2024
[xii] Next are some finer points of the author’s Hayekian perspective. First, F.A. Hayek came of age in pre-World War II Europe. He was born in Austria and moved to London as Nazism grew in post-World War I Europe. The counterpoint perspective between Galton and Hayek is strong.
Hayek was a classical libertarian who believed individual choice and responsibility were essential for the efficient functioning of sovereign economies. Hayek believed there was an important place for the rule of ex-ante law.
The author's Hayekian interpretation is that law should be considered like guard rails. Society should carefully consider and only implement necessary guard rails. Then, individuals should freely choose within those guard rails. Like The 10th amendment to the U.S. Constitution, Hayek would have liked the ex-ante provision where "The powers not delegated to the United States by the Constitution" are reserved for the people.
Also, people will certainly make mistakes and poor choices. But their mistakes and choices are still superior to those of a government bureaucrat, making choices on the individual’s behalf. This is for three reasons:
Information power: The individual has more local information about the decision and how it will likely impact them. The bureaucrat will use summary information to make a policy decision on the average for a diverse population.
Error-correction power: The feedback loop effectiveness for the individual in the case of a poor decision is much greater. The power of the error-correcting incentives is far greater for the individual than that of the bureaucrat on behalf of the individual.
Ownership power: An individual is likely to be highly motivated when they have a sense of ownership over their choice. Conversely, an individual will be highly de-motivated when that choice is made for them.
For a deeper F.A. Hayek perspective in the context of a modern example, please see:
Hulett, A Question Of Choice: Optimizing resource allocation and an HOA example, The Curiosity Vine, 2023
Comments